
spark를 파이썬 환경에서 사용하려고 할 때 설치 방법을 소개한다.
파이썬은 이미 설치되어 있다고 가정한다.
또 자바도 설치해야 하는데, 자바는 8/11 만 지원한다고 하니 참고하시길
(나머지 버전을 아예 지원 안하는지는 잘 모르겠다, 나는 8이 깔려있어서 그냥 진행하기로 하였다)
1) Apache Spark 다운로드
아파치 스파크 공식 홈페이지에서 적절한 버전을 다운로드 한다.
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
그런데 이때 중요한 점이 있다. 맥이나 리눅스 사용자는 상관없을 것 같은데, 윈도우 사용자는 spark를 윈도우에서 사용하기 위해서는 winutils.exe를 설치해야 하는데, 현재 이 글을 쓰는 2022.07.24에 spark는 3.3.0까지 나와있지만 winutils.exe는 3.2.2까지만 나와있다.
나는 처음에 그걸 모르고 최신 버전 spark를 설치 했다가 다시 3.2.2로 설치했다.
그러니 winutil이 지금 설치하려는 버전까지 나와있는지 확인하고 spark를 다운 받는 것이 좋을 듯 하다.
1. spark 버전 선택
2. hadoop 버전 선택
3. 다운로드
이때 hadoop 버전도 맞춰주는 것이 좋다.
저렇게 검색하면 필요한 버전을 알 수 있으니 참고!
3번의 링크를 클릭하면 다음과 같은 화면이 나온다.
저 셋중에 아무거나라도 누르면 바로 다운이 시작된다.
(BACKUP SITE는 왜 경로가 같은 걸까.. 백업사이트는 아닌거같은데 ㅋㅋ 아시는 분)
이때 윈도우에서는 .tgz를 다루는 압축 프로그램이 기본적으로 설치되어 있지 않기 때문에 없는 사람은 여기서 다운로드 받길 바란다. (다운받으면 바로 적용될 것이다)
WinRAR archiver, a powerful tool to process RAR and ZIP files
We want you to have the best possible experience while using our service. Our website uses cookies to help improve your visit. By using this website, you consent to the use of cookies. For more detailed information regarding the use of cookies on this webs
www.rarlab.com
다운 받은 tgz 파일을 위 프로그램으로 압축해제를 하고 들어가보면 이런 파일구조를 볼 수 있다.
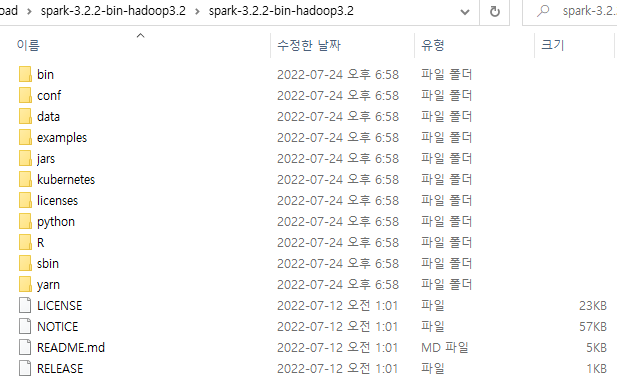
이 아이들을 Ctrl + A / C 해서 모두 선택/복사해주고,
이제 C드라이브로 가서(window가 설치되어 있는 드라이브)
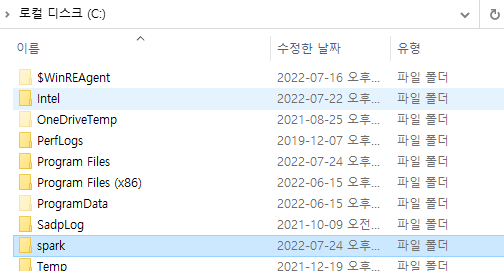
spark라는 폴더를 새로 생성한다.
아까 복사한 애들을 이 안에 붙여넣기 해준다.

여기서 conf 폴더 안에 들어가면 .templete 파일들이 몇개 있다.
그 중 log4j로 시작하는 파일의 .templete을 지워서 log4j.properties로 파일명이 되게끔 한다.
그리고 메모장이든 뭐든 텍스트 에디터로 이 파일을 연다.

log4j.rootCategory=INFO, console로 되어 있을 것이다.
INFO -> ERROR로 바꾼다. 이렇게 하면 작업을 수행할 때, 출력되는 로그를 없애준다.
2) winutils.exe 설치 (윈도우 사용자만!)
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
github.com
이 툴을 설치하면 spark가 윈도우에 하둡이 설치되어 있다고 착각하게 끔 만든다고 한다.
내가 집에서 연습하는 것은 스크립트를 데스크탑에서 그냥 실행할 거라 굳이 하둡이 필요없기 때문이다.
위 경로에서 위에서 언급했던 것처럼 자신이 설치한 spark 버전에 맞는 버전을 다운받아야 한다.
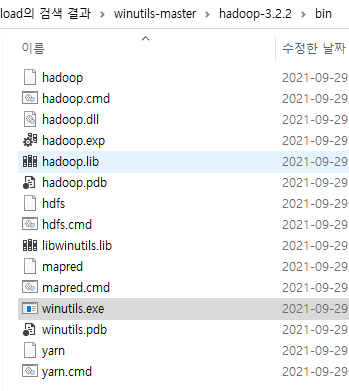
압축을 풀면 bin 폴더가 하나 있고 그 안에 여러 파일이 있는데, 우리는 winutils.exe만 필요하다.
전체를 복사해도 큰 문제는 없을듯하다
다시 C드라이브(윈도우 폴더)에 가서 winutils폴더를 생성하고 그 안에 위 구조와 똑같이 bin 폴더를 생성한다.
그리고 복사한 winutils.exe를 winutils/bin 하위에 붙여넣기 한다.
+ 2022.10.14 이 때는 내가 hadoop을 사용하지 않아서 winutils.exe만 옮겼는데, 나중에 stream 작업을 하다가 spark.readStream.text('path')에서 다음과 같은 에러가 났다.
py4j.protocol.Py4JJavaError: An error occurred while calling o30.text.
: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:793)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1215)
at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1420)
at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:601)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1972)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:2014)
at org.apache.hadoop.fs.ChecksumFileSystem.listStatus(ChecksumFileSystem.java:761)
at org.apache.spark.util.HadoopFSUtils$.listLeafFiles(HadoopFSUtils.scala:225)
at org.apache.spark.util.HadoopFSUtils$.$anonfun$parallelListLeafFilesInternal$1(HadoopFSUtils.scala:95)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:286)
at scala.collection.TraversableLike.map$(TraversableLike.scala:279)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFilesInternal(HadoopFSUtils.scala:85)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFiles(HadoopFSUtils.scala:69)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$.bulkListLeafFiles(InMemoryFileIndex.scala:158)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.listLeafFiles(InMemoryFileIndex.scala:131)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.refresh0(InMemoryFileIndex.scala:94)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.<init>(InMemoryFileIndex.scala:66)
at org.apache.spark.sql.execution.datasources.DataSource.createInMemoryFileIndex(DataSource.scala:565)
at org.apache.spark.sql.execution.datasources.DataSource.$anonfun$sourceSchema$2(DataSource.scala:268)
at org.apache.spark.sql.execution.datasources.DataSource.tempFileIndex$lzycompute$1(DataSource.scala:164)
at org.apache.spark.sql.execution.datasources.DataSource.tempFileIndex$1(DataSource.scala:164)
at org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:169)
at org.apache.spark.sql.execution.datasources.DataSource.sourceSchema(DataSource.scala:262)
at org.apache.spark.sql.execution.datasources.DataSource.sourceInfo$lzycompute(DataSource.scala:118)
at org.apache.spark.sql.execution.datasources.DataSource.sourceInfo(DataSource.scala:118)
at org.apache.spark.sql.execution.streaming.StreamingRelation$.apply(StreamingRelation.scala:34)
at org.apache.spark.sql.streaming.DataStreamReader.loadInternal(DataStreamReader.scala:195)
at org.apache.spark.sql.streaming.DataStreamReader.load(DataStreamReader.scala:209)
at org.apache.spark.sql.streaming.DataStreamReader.text(DataStreamReader.scala:339)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)잘보면 hadoop 관련 라이브러리에서 UnsatisfiedLinkError가 났다. 즉, hadoop 라이브러리 연결 중 에러가 났다는 것이다. 아차 싶어서 hadoop-version/bin 폴더 안 파일들을 모두 옮겨줬더니 해결되었다.
potential error 발생을 방지하기 위해 파일 사용 권한을 줘야 한다.
C드라이브에 tmp/hive 폴더를 생성한다.
그리고 윈도우 cmd 창을 열고 winutils.exe가 위치한 경로로 간다.
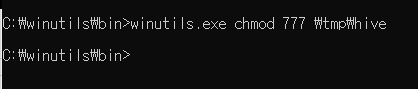
위 명령어를 실행해주면 된다.
3) 환경변수 설정
스파크/하둡의 환경변수 경로를 추가해준다.
우선 제어판-시스템-고급시스템설정-환경변수로 들어간다. (다들 익숙하시쥬?)
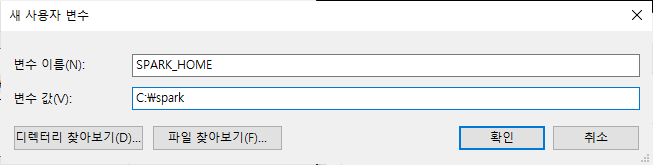
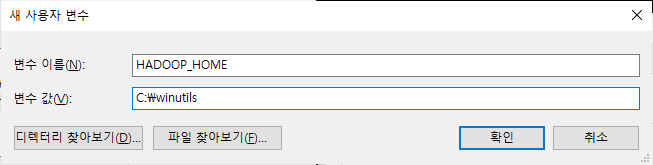
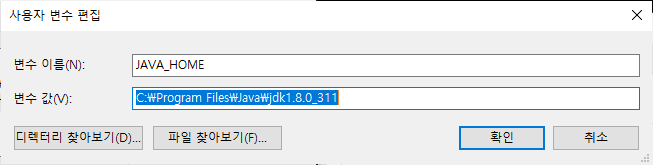
JAVA_HOME이 없는 사람은 꼭 추가해주세여.
또 Path에 다음을 2항목을 추가합니다.
%SPARK_HOME%\bin
%HADOOP_HOME%\bin
%JAVA_HOME%\bin (얘가 없다면 얘도 추가!)
4) 잘 설치되었는지 테스트 하기
커맨드 창을 열고 spark를 설치한 경로로 가서
pyspark를 실행하면 다음과 같이 나온다면
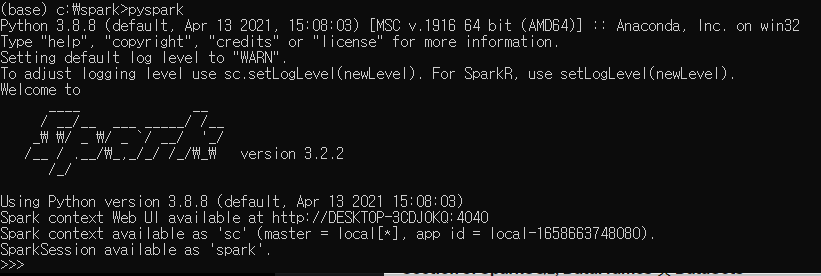
우선 spark 실행은 성공이고 사용이 잘 되는지 보자.
spark 경로에 있는 README.md 파일의 행수를 알아보는 간단한 프로그램을 작성해보자.
꼭 저 파일일 필요는 없고 텍스트 형식으로 된 파일이면 된다.
rdd = sc.textFile("README.md")
rdd.count()위 코드 실행이 실패한다면 3)번으로 가서 환경변수에 PYSPARK_PYTHON을 추가하고 설치되어 있는 파이썬 경로를 값으로 넣으면 된다.
'개발 관련 이야기' 카테고리의 다른 글
| [NSIS] 자동실행 시 파라미터 전달 (0) | 2022.08.05 |
|---|---|
| Window - 환경변수 설정 없이 Visual Studio에서 OpenCV 사용하기 (0) | 2022.08.04 |
| MFC - Border 속성이 Resizing이 아닌데도 계속 리사이징 될 때 (0) | 2022.08.03 |
| Thread 내에서 Toast 띄우기 (0) | 2022.08.02 |
| AWS 사용자 종류 (0) | 2022.07.26 |



댓글